倒排索引¶
约 716 个字 25 行代码 预计阅读时间 3 分钟
倒排文件是一种数据结构,它存储了某个特定词汇在文本中所有出现位置的索引。这些索引可以是页面编号、行号或文本中的具体位置等。简而言之,倒排文件就是一种记录了词汇出现位置的地图,便于快速检索到该词汇在文档中的所有出现点。
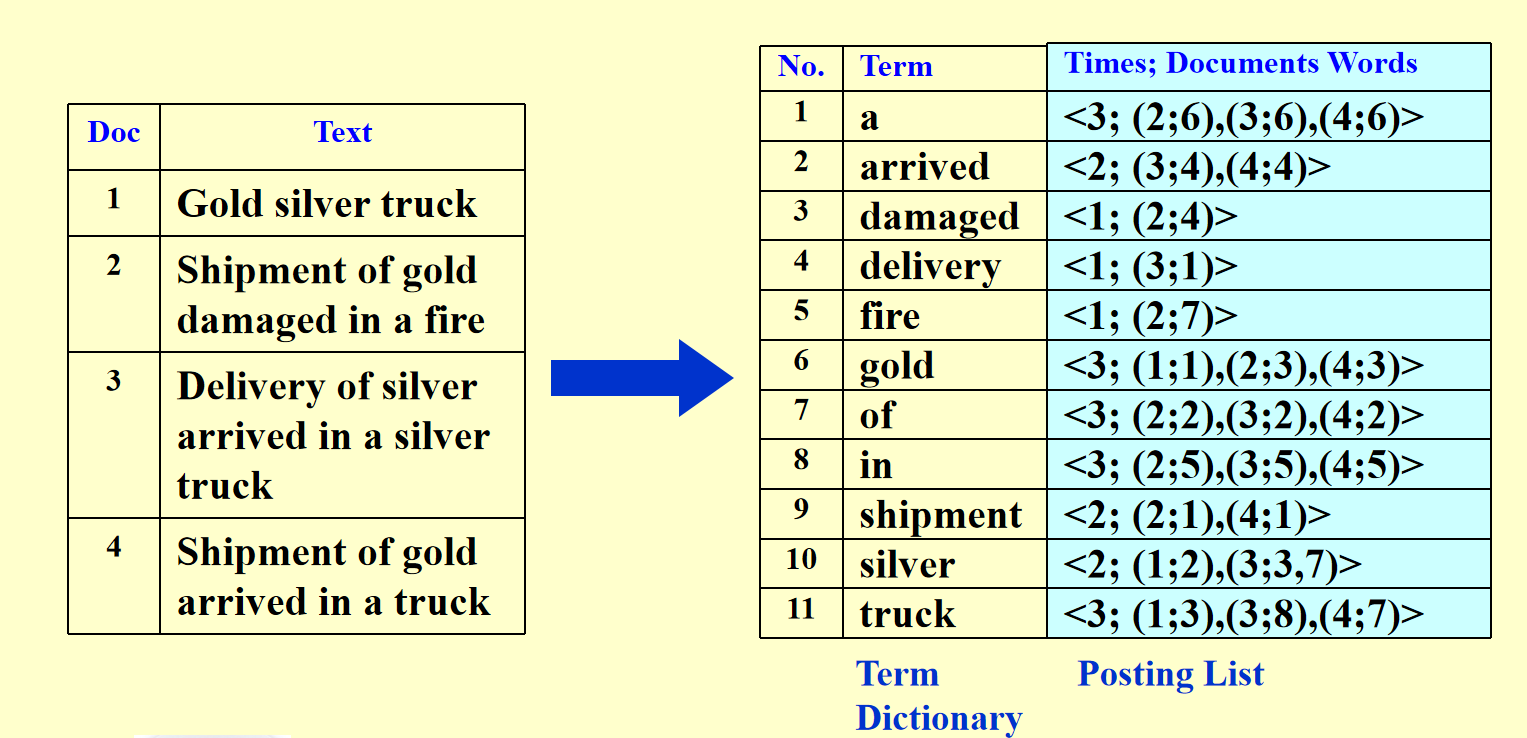
储存其出现的频率是因为从出现次数较少的词汇中找到的文档更有可能是相关文档。而且,出现次数较少的词汇更有可能是特定的词汇,因此更有可能是相关文档。
构建倒排索引:
while ( read a document D ) {
while ( read a term T in D ) {
if ( Find( Dictionary, T ) == false )
Insert( Dictionary, T );
Get T’s posting list;
Insert a node to T’s posting list;
}
}
Write the inverted index to disk;
需要考虑很多问题
-
Steaming: 词汇的变形问题,如“run”和“running”是同一个词汇的不同形式。没必要分别储存
-
Stop words:在搜索引擎中没有实际意义的词汇,如“a”、“an”、“the”等。在倒排文件中,这些词汇的储存会占用大量的空间,而且对搜索结果没有实际意义。
-
搜索的方式:search树、哈希表;树查询比较慢,范围查询比较块;哈希表查询比较快,但是范围查询比较慢,而且需要考虑哈希冲突的问题。
-
内存管理
BlockCnt = 0;
while ( read a document D ) {
while ( read a term T in D ) {
if ( out of memory ) {
Write BlockIndex[BlockCnt] to disk;
BlockCnt ++;
FreeMemory;
}
if ( Find( Dictionary, T ) == false )
Insert( Dictionary, T );
Get T’s posting list;
Insert a node to T’s posting list;
}
}
for ( i=0; i<BlockCnt; i++ )
Merge( InvertedIndex, BlockIndex[i] );
- 分布式索引:将倒排索引分布在多个服务器上,每个服务器负责一部分索引。这样可以提高搜索的效率,减少单个服务器的负载。

- 压缩存储

将stop words去掉,存储时存储每个单词的长度而不是其首字母出现的位置,这样可以避免大数字的存储。
- 文档阈值的控制

-
文档阈值控制:
- 只检索按照权重排名的前
x个文档。 - 不适用于布尔查询,因为布尔查询通常需要返回所有匹配的文档,而不是按相关性排序的子集。
- 缺点是由于截断可能会遗漏一些相关的文档,即只选择排名靠前的文档,可能会忽略重要的文档。
- 只检索按照权重排名的前
-
查询阈值控制:
- 将查询词按照词频升序排列(从最不常见的词到最常见的词)。
- 系统根据原始查询词的某个百分比进行搜索。图中显示了按 20%、40%、80% 的比例使用查询词(从 T1 到 T10)
搜索的性能衡量指标有两个:召回率**和**准确率。召回率(能搜索到多少)是指检索到的相关文档数与系统中所有相关文档数的比值,准确率(正确的是多少)是指检索到的相关文档数与检索到的文档总数的比值。
| Relevant | Irrelevant | |
|---|---|---|
| Retrieved | \(R_R\) | \(I_R\) |
| Not Retrieved | \(R_N\) | \(I_N\) |
Perscision = \(\dfrac{R_R}{R_R+I_R}\)
Recall = \(\dfrac{R_R}{R_R+R_N}\)